Storage & Integrity: Difference between revisions
JMcDougall (Sọ̀rọ̀ | contribs) No edit summary |
JMcDougall (Sọ̀rọ̀ | contribs) No edit summary |
||
| (12 intermediate revisions by 2 users not shown) | |||
| Line 1: | Line 1: | ||
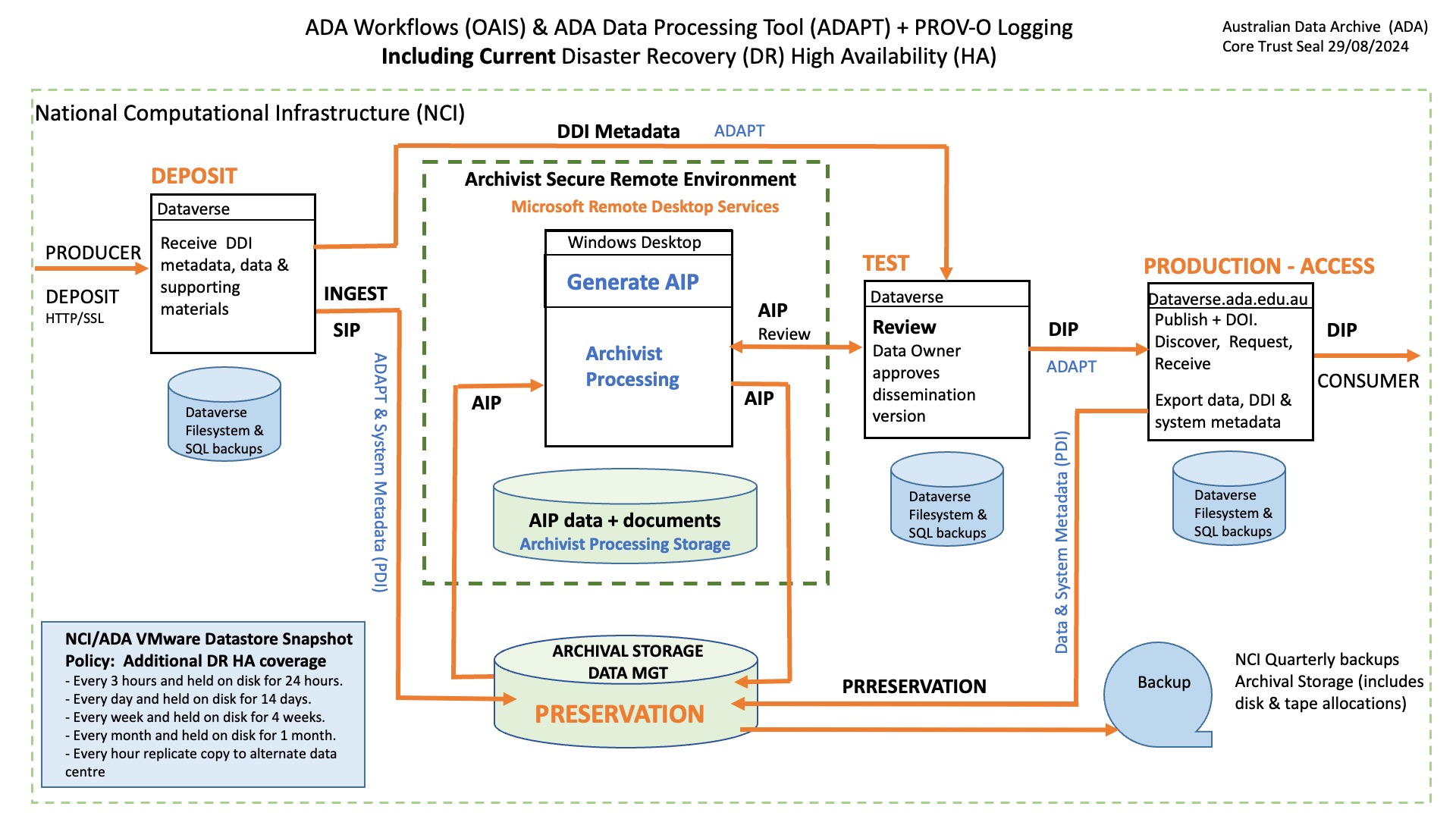
The ADA archival workflow [34] outlines processes to manage the integrity of the data and metadata flow through the Archive. [https://docs.ada.edu.au/images/f/f4/CTS_2024_ADA%2BNCI_-_RDS%2BStorage_solutions_JM_%28V4%29_2024-09-06_wiki.jpeg The ADA Workflow and Storage Diagram] [47] reflects the distinct deposit, ingest, curation, access, and storage locations for each of the archival phases. | |||
==ADA Archive Training == | |||
The ADA Archivist team are trained with respect to the OAIS Reference Model and how it is implemented within ADA’s technical architecture: | |||
*Deposited data = SIP | |||
*Ingest (curation, processing, data management, preservation) = AIP | |||
*Access = DIP | |||
The Archivist team members are trained to know where and how the data is stored for each of the SIP, AIP and DIP, and actively contribute to ongoing documentation and development of processes. The archivist team are also trained in accessing and processing the raw Information Packages within ADA’s secure Remote Desktop Service. | |||
The ADA access management team manages access to the DIP (dissemination version). The access management team is trained in processes regarding documented Business Rules that dictate an applicant’s being granted or rejected in their application to access the DIP. | |||
The technical management team follows established informally documented workflows to contact the NCI Helpdesk when any storage-related issues arise. | |||
==Data & Storage Management== | |||
The Dataverse software [49] supports reporting, data management and auditing through user accounts for access, authentication, and permissions; to edit, upload, and download data. | |||
ADA previously developed the ADA Data Processing Tool (ADAPT) [6] based on the OAIS Reference Model [42]. ADAPT enables archivists to programmatically manage movement of data and metadata between Dataverse instances and archival storage to manage data integrity. Each user actioned ADAPT function creates or appends to a log using a standard provenance ontology (PROV-O) [3]. The log is stored as part of the AIP to support auditing of archival activities actioned through ADAPT, if required. ADAPT is moving towards its third version as ADA continues to develop strategies to minimise the risk of manual data and metadata management versus building management into a software application. | |||
Data and metadata are stored with each Dataverse instance, and versioned at publication of a dataset. ADAPT is used to move data and metadata between the Dataverse instances as required at each archival phase. | |||
Dataverse exports metadata in a number of formats. The JSON export format of the DDI metadata also includes Dataverse system metadata such as fixity checks on uploaded data files (checksum MD5). The JSON metadata formats are exported by archivists during the Ingest phase and Publish phase. The JSON export is copied to archival storage for preservation of the original (SIP) metadata and data files, and the published (DIP) metadata and data files, to ensure that the integrity of digital objects from deposit to access can be verified against any changes to the data. | |||
The archivist Data Curation Process [34] encapsulates data processing, including superseded and new versions of data, in conjunction with support from Dataverse software versioning control. | |||
==Strategy For Multiple Copies == | |||
ADA has defined a process for the Archivist team to follow to manage multiple copies of the data corresponding to OAIS: | |||
*SIP: A dataset deposited to ADA via Deposit Dataverse is assigned a unique ADAID. When deposited data is uploaded to Deposit Dataverse, uploading creates a copy in the backend server directory /files/xxxxxx/ on deposit.ada.edu.au (where xxxxxx is the DOI suffix created by Dataverse for the dataset). A copy of the deposited data is also automatically stored in ADA-only project storage (../<ADAID>/original). The files in the Dataverse directory will be the same as the files in the project storage. | |||
*AIP: Dataset metadata and files are copied from deposit.ada.edu.au to dataverse-test.ada.edu.au. Copying to Test Dataverse creates a copy in the backend server directory /files/yyyyyy/ on dataverse-test.ada.edu.au (where yyyyyy is the DOI suffix created by Dataverse for that dataset). A copy of those files is created in the ADA-only project storage (../<ADAID>/processing). The files on dataverse-test and /files/yyyyyy are dynamic while the archivists process these files. Processing syntax and any other documentation is also uploaded to ../<ADAID>/processing. | |||
*DIP: Once AIP processing is complete, Dataset metadata is copied from dataverse-test.ada.edu.au to the Production Dataverse, dataverse.ada.edu.au. Copying the files creates a copy in the backend server /files/zzzzzz directory on dataverse.ada.edu.au (where zzzzzz is the doi suffix created by Dataverse for that dataset). The files on dataverse.ada.edu.au /files/zzzzzz will be exported and copied to the ADA-only project storage top-level directory (../<ADAID>/) for preservation. | |||
*UPDATING PUBLISHED DATA: When data for a dataset that has been published on Production dataverse.ada.edu.au (DIP) is to be updated, a new dataset (no metadata) is created on deposit.ada.edu.au into which the depositor uploads the new datafiles; this creates a copy of the files in the /files/bbbbbb on the Dataverse server. A new directory is created on project storage (../<ADAID>/superseded_<creation_date>) and all files from the previous round deposit, processing and publication are moved into that folder. | |||
The update data is moved using ADAPT from Deposit deposit.ada.edu.au into the /<ADAID>/original and the deposit -> processing -> publish workflow starts again. To process the AIP, the previous files on dataverse-test are replaced with the update deposit files. The new DIP files from /<ADAID>/original are uploaded to the existing dataset on dataverse.ada.edu.au, and that dataset is versioned up to a new major version (x.0). This also places the new files in the /files/zzzzzz directory on the Dataverse server. | |||
Backup copies and snapshots of the data on the ADA-only project storage space are created for disaster recovery. | |||
== Risk Management== | |||
The OAIS model is implemented with data stored for each of the SIP, AIP, DIP ../<ADAID>/ directories, and on the Dataverse backend servers. The archive team are trained to strictly follow documented archive procedures to manage the copies across the directories. The ADA workflow procedures [34] minimises the probability of data copies becoming unsynchronised. | |||
== Deterioration Handling == | |||
ADA Archival Storage and Dataverse instances [47] are provisioned, hosted and backed up on NCI servers. NCI has procedures for monitoring bit level integrity against the deterioration of their storage media. NCI notifies ADA if there are plans for any necessary upgrades and when those upgrades will take place. | |||
The ADA technical team works with NCI to keep server operating systems updated to supported versions. NCI informs the ADA technical team when a Virtual Machine (VM) operating system (OS) is no longer going to be supported. NCI provisions new VMs when necessary, and the ADA technical team moves Dataverse installations to these new VMs. | |||
== Deletion Processes== | |||
Data in the SIP or AIP state can be deleted by the ADA archivist team if directed by depositors, or for legal reasons. The archiving team retains any records relating to the request for deletion. Data in the DIP state cannot be deleted. | |||
As datasets on Deposit and Test Dataverse are not published, deleting a dataset from Deposit does not create problems with the temporary non-production DOI that is created for it. Simply deleting the dataset would delete everything relating to it including the files stored in the backend server /files/xxxxxxx directory. The DOI would not have to be tombstoned [4] as the DOI prefix is a fake or test prefix, unrelated to ADA’s production DOI prefix. The data stored in the ../<ADAID>/ subdirectories are deleted by the responsible archivist. | |||
If required, the ADA will deaccession (rather than delete) datasets that have been published on the production Dataverse. This results in the dataset being labelled as “Deaccessioned” in Dataverse and renders its files accessible only to users with the correct permission levels (generally only ADA staff). The files remain in the Dataverse server /files/zzzzzz/ directory. | |||
==References== | |||
[3] PROV-O – (https://www.w3.org/TR/2013/REC-prov-o-20130430/) | |||
[4] Datacite Tombstone – (https://support.datacite.org/docs/tombstone-pages) | |||
[49] The Dataverse Project – (https://dataverse.org) | |||
[34] Workflows – (https://docs.ada.edu.au/index.php/Workflows) | |||
[47] ADA OAIS Workflows ADAPT DR Diagram – (https://docs.ada.edu.au/images/f/f4/CTS_2024_ADA%2BNCI_-_RDS%2BStorage_solutions_JM_%28V4%29_2024-09-06_wiki.jpeg) | |||
Latest revision as of 22:59, 28 October 2024
The ADA archival workflow [34] outlines processes to manage the integrity of the data and metadata flow through the Archive. The ADA Workflow and Storage Diagram [47] reflects the distinct deposit, ingest, curation, access, and storage locations for each of the archival phases.
{kind=link}
ADA Archive Training
The ADA Archivist team are trained with respect to the OAIS Reference Model and how it is implemented within ADA’s technical architecture:
- Deposited data = SIP
- Ingest (curation, processing, data management, preservation) = AIP
- Access = DIP
The Archivist team members are trained to know where and how the data is stored for each of the SIP, AIP and DIP, and actively contribute to ongoing documentation and development of processes. The archivist team are also trained in accessing and processing the raw Information Packages within ADA’s secure Remote Desktop Service.
The ADA access management team manages access to the DIP (dissemination version). The access management team is trained in processes regarding documented Business Rules that dictate an applicant’s being granted or rejected in their application to access the DIP.
The technical management team follows established informally documented workflows to contact the NCI Helpdesk when any storage-related issues arise.
Data & Storage Management
The Dataverse software [49] supports reporting, data management and auditing through user accounts for access, authentication, and permissions; to edit, upload, and download data.
ADA previously developed the ADA Data Processing Tool (ADAPT) [6] based on the OAIS Reference Model [42]. ADAPT enables archivists to programmatically manage movement of data and metadata between Dataverse instances and archival storage to manage data integrity. Each user actioned ADAPT function creates or appends to a log using a standard provenance ontology (PROV-O) [3]. The log is stored as part of the AIP to support auditing of archival activities actioned through ADAPT, if required. ADAPT is moving towards its third version as ADA continues to develop strategies to minimise the risk of manual data and metadata management versus building management into a software application.
Data and metadata are stored with each Dataverse instance, and versioned at publication of a dataset. ADAPT is used to move data and metadata between the Dataverse instances as required at each archival phase.
Dataverse exports metadata in a number of formats. The JSON export format of the DDI metadata also includes Dataverse system metadata such as fixity checks on uploaded data files (checksum MD5). The JSON metadata formats are exported by archivists during the Ingest phase and Publish phase. The JSON export is copied to archival storage for preservation of the original (SIP) metadata and data files, and the published (DIP) metadata and data files, to ensure that the integrity of digital objects from deposit to access can be verified against any changes to the data.
The archivist Data Curation Process [34] encapsulates data processing, including superseded and new versions of data, in conjunction with support from Dataverse software versioning control.
Strategy For Multiple Copies
ADA has defined a process for the Archivist team to follow to manage multiple copies of the data corresponding to OAIS:
- SIP: A dataset deposited to ADA via Deposit Dataverse is assigned a unique ADAID. When deposited data is uploaded to Deposit Dataverse, uploading creates a copy in the backend server directory /files/xxxxxx/ on deposit.ada.edu.au (where xxxxxx is the DOI suffix created by Dataverse for the dataset). A copy of the deposited data is also automatically stored in ADA-only project storage (../<ADAID>/original). The files in the Dataverse directory will be the same as the files in the project storage.
- AIP: Dataset metadata and files are copied from deposit.ada.edu.au to dataverse-test.ada.edu.au. Copying to Test Dataverse creates a copy in the backend server directory /files/yyyyyy/ on dataverse-test.ada.edu.au (where yyyyyy is the DOI suffix created by Dataverse for that dataset). A copy of those files is created in the ADA-only project storage (../<ADAID>/processing). The files on dataverse-test and /files/yyyyyy are dynamic while the archivists process these files. Processing syntax and any other documentation is also uploaded to ../<ADAID>/processing.
- DIP: Once AIP processing is complete, Dataset metadata is copied from dataverse-test.ada.edu.au to the Production Dataverse, dataverse.ada.edu.au. Copying the files creates a copy in the backend server /files/zzzzzz directory on dataverse.ada.edu.au (where zzzzzz is the doi suffix created by Dataverse for that dataset). The files on dataverse.ada.edu.au /files/zzzzzz will be exported and copied to the ADA-only project storage top-level directory (../<ADAID>/) for preservation.
- UPDATING PUBLISHED DATA: When data for a dataset that has been published on Production dataverse.ada.edu.au (DIP) is to be updated, a new dataset (no metadata) is created on deposit.ada.edu.au into which the depositor uploads the new datafiles; this creates a copy of the files in the /files/bbbbbb on the Dataverse server. A new directory is created on project storage (../<ADAID>/superseded_<creation_date>) and all files from the previous round deposit, processing and publication are moved into that folder.
The update data is moved using ADAPT from Deposit deposit.ada.edu.au into the /<ADAID>/original and the deposit -> processing -> publish workflow starts again. To process the AIP, the previous files on dataverse-test are replaced with the update deposit files. The new DIP files from /<ADAID>/original are uploaded to the existing dataset on dataverse.ada.edu.au, and that dataset is versioned up to a new major version (x.0). This also places the new files in the /files/zzzzzz directory on the Dataverse server.
Backup copies and snapshots of the data on the ADA-only project storage space are created for disaster recovery.
Risk Management
The OAIS model is implemented with data stored for each of the SIP, AIP, DIP ../<ADAID>/ directories, and on the Dataverse backend servers. The archive team are trained to strictly follow documented archive procedures to manage the copies across the directories. The ADA workflow procedures [34] minimises the probability of data copies becoming unsynchronised.
Deterioration Handling
ADA Archival Storage and Dataverse instances [47] are provisioned, hosted and backed up on NCI servers. NCI has procedures for monitoring bit level integrity against the deterioration of their storage media. NCI notifies ADA if there are plans for any necessary upgrades and when those upgrades will take place.
The ADA technical team works with NCI to keep server operating systems updated to supported versions. NCI informs the ADA technical team when a Virtual Machine (VM) operating system (OS) is no longer going to be supported. NCI provisions new VMs when necessary, and the ADA technical team moves Dataverse installations to these new VMs.
Deletion Processes
Data in the SIP or AIP state can be deleted by the ADA archivist team if directed by depositors, or for legal reasons. The archiving team retains any records relating to the request for deletion. Data in the DIP state cannot be deleted.
As datasets on Deposit and Test Dataverse are not published, deleting a dataset from Deposit does not create problems with the temporary non-production DOI that is created for it. Simply deleting the dataset would delete everything relating to it including the files stored in the backend server /files/xxxxxxx directory. The DOI would not have to be tombstoned [4] as the DOI prefix is a fake or test prefix, unrelated to ADA’s production DOI prefix. The data stored in the ../<ADAID>/ subdirectories are deleted by the responsible archivist.
If required, the ADA will deaccession (rather than delete) datasets that have been published on the production Dataverse. This results in the dataset being labelled as “Deaccessioned” in Dataverse and renders its files accessible only to users with the correct permission levels (generally only ADA staff). The files remain in the Dataverse server /files/zzzzzz/ directory.
References
[3] PROV-O – (https://www.w3.org/TR/2013/REC-prov-o-20130430/)
[4] Datacite Tombstone – (https://support.datacite.org/docs/tombstone-pages)
[49] The Dataverse Project – (https://dataverse.org)
[34] Workflows – (https://docs.ada.edu.au/index.php/Workflows)
[47] ADA OAIS Workflows ADAPT DR Diagram – (https://docs.ada.edu.au/images/f/f4/CTS_2024_ADA%2BNCI_-_RDS%2BStorage_solutions_JM_%28V4%29_2024-09-06_wiki.jpeg)